| Version 8 (modified by , 17 years ago) (diff) |
|---|
TP2: Introduction d'un coprocesseur matériel spécialisé
TP Précédent: MjpegCourse/Multipipe
0. Objectif
L'objectif de ce TP est de vous montrer comment introduire un coprocesseur matériel spécialisé dans une architecture matérielle comportant principalement des processeurs programmables.
L'introduction d'un accélérateur matériel n'est pas toujours justifiée. La loi d'Amdhal précise qu'il est inefficace d'accélérer un traitement qui ne représente qu'une petite partie du temps de calcul total de l'application. De plus, il faut prendre en compte les temps de communication entre le coprocesseur et le reste de l'application.
La tâche IDCT étant la plus gourmande en temps de calcul, nous allons analyser les gains de performance apportés par l'implantation de cette tâche comme un processeur matériel spécialisé.
Pour éviter de re-écrire toute l'application logicielle, on s'impose que le coprocesseur matériel utilise les mêmes canaux de communication (en entrée et en sortie), que ceux utilisés par la tâche logicielle. Il faut donc que le coprocesseur matériel respecte le protocole MWMR à 5 étapes:
- prise du verrou,
- consultation de l'éta de la FIFO logicielle,
- transfert des données,
- mise à jour de l'état de la FIFO logicielle,
- libération du verrou.
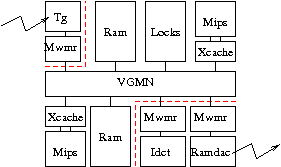
Pour simplifier le travail des outils de synthèse, on utilise pour cela un composant matériel générique, appelé contrôleur MWMR qui est un initiateur VCI, capable de lire ou d'écrire en mémoire, dans des FIFO MWMR, et qui fournit au coprocesseur autant de canaux de communications que celui-ci en a besoin. C'est ce même composant matériel qui est utilisé par les composants RAMDAC et TG.
Nous repartirons de la plateforme du TP3: VgmnNoirqMulti.
Nous modifierons cette plateforme comportant deux processeurs Mips, pour ajouter
un coprocesseur matériel dédié au traitement de l'Idct.
Reprenez les fichiers du TP2:
- La description de la plateforme
- La description de l'application
- Le code des tâches (
Libune gère qu'un seul pipeline etSplitn'existe pas)
 Pour un déploiement entièrement logiciel, rappelez le temps
nécessaire pour décoder 25 images.
Pour un déploiement entièrement logiciel, rappelez le temps
nécessaire pour décoder 25 images.
1. Modification du TCG
Il faut commencer par modifier le modèle de la tâche idct,
en définissant une implémentation matérielle,
sous forme d'un coprocesseur matériel:
idct = TaskModel( 'idct', infifos = [ 'input' ], outfifos = [ 'output' ], impl = [ SwTask( 'idct', stack_size = 1024, sources = [ 'src/idct.c' ], defines = [ 'WIDTH', 'HEIGHT' ] ), HwTask( IdctCoproc ) ] )
2. Coprocesseur virtuel
Il existe plusieurs solutions micro-architecturales pour la synthèse d'un coprocesseur matériel spécialisé. Dans le cas d'une transformation IDCT, on peut, suivant le nombre d'opérateurs arithmétiques utilisés, effectuer le calcul d'un bloc de 64 pixels en un cycle, en 8 cycles, en 64 cycles ou en 256 cycles. Le coût matériel est inversement proportionnel au temps de calcul.
Avant de se lancer dans la synthèse, il faut donc évaluer précisément
la puissance de calcul requise pour le coprocesseur, une fois celui-ci placé
dans son environnement de travail. On commence donc par encapsuler
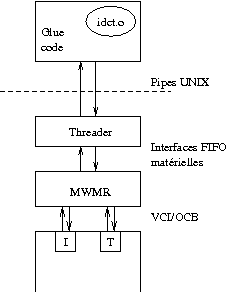
la tâche matérielle idct dans un composant matériel générique appelé threader.
Ce composant s'interface d'un côté avec le contrôleur MWMR, et de l'autre avec
la tâche logicielle
Remplacez la déclaration HwTask( IdctCoproc ) par une déclaration de coprocesseur matériel virtuel Synthetic().
L'implémentation Synthetic() doit être accompagnée d'une déclaration de tâche logicielle
(SwTask) et permet la synthèse virtuelle de la tâche. On peut alors déployer la tâche comme si
elle était matérielle, son comportement est simulé.
Le coprocesseur matériel IDCT, comme beaucoup de coprocesseurs matériels de type flot de données) exécute une boucle infinie dans laquelle if effectue successivement les actions suivantes:
- recopie d'un bloc de 64 coefficients du canal MWMR d'entrée vers une mémoire locale BUFIN,
- calcul d'un bloc de 64 pixels, et stockage de ces pixels dans une seconde mémoire locale BUFOUT
- recopie de ces 64 pixels de la mémoire locale BUFOUT vers le canal MWMR de sortie.
Pour modéliser le temps de traitement la tâche matérielle virtuelle plus exacte en temps de simulation, on peut ajouter des directives
dans le code source C des tâches pour préciser le temps qu'il faudrait pour réaliser la même action en matériel:
srl_busy_cycles (voir SrlApi).
En lisant le code de l'implémentation matérielle du coprocesseur Idct, déduisez les temps
nécessaires aux différentes parties du traitement.
En utilisant un coprocesseur virtuel, pour la tâche idct,
détermidez quel est le gain en performances apporté par le coprocesseur, pour
différents temps de traitement (1cycle, 8 cycles, 64 cycles, 512 cycles ou 2048 cycles
pour traiter un bloc de 64 pixels).quel est le temps
nécessaire pour décoder 25 images ? Quel rapport à la simulation avec un vrai coprocesseur matériel ?
3. Coprocesseur matériel
Ajoutez les directives temporelles dans src/idct.c.
Quel est maintenant le temps de simulation nécessaire pour 25 images ?
Qu'en déduisez-vous sur la différence entre les deux possibilités pour tester
une implémentation matérielle ?
Quel intérêt y a-t-il à pouvoir caractériser précisément le temps de traitement
d'une tâche matérielle à partir d'un code en C ?
4. Compte-Rendu
Comme pour les TP précédents, vous rendrez une archive contenant:
$ tar tzf binome0_binome1.tar.gz tp5/ tp5/rapport.pdf tp5/vgmn_noirq_multi.py tp5/mjpeg/ tp5/mjpeg/mjpeg.py tp5/mjpeg/src/ tp5/mjpeg/src/iqzz.c tp5/mjpeg/src/idct.c tp5/mjpeg/src/libu.c
Cette archive devra être livrée avant le mardi 13 mars 2007, 18h00 à [MailAsim:nipo Nicolas Pouillon]
Attachments (2)
- threader.png (3.5 KB) - added by 17 years ago.
- vgmn_coproc.png (3.0 KB) - added by 17 years ago.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download all attachments as: .zip